|
Personal Information
🎓 Greetings, I have completed my integrated Ms-Ph.D. Degree in Electrical Engineering at KAIST in 2018-2025 in South Korea,
under the guidance of Professor Chang D. Yoo. My interest relates to Computer Vision, Deep Learning, Machine Learning, Generative AI,
and Image/Video/Audio processing: Self-supervised Learning, Generative Models, Diffusion Models, Multimodal Learning,
Speech Processing and Natural Language Processing. I continued doing Postdoctoral research at KAIST after my doctoral degree is finished.
🎓 In the past, I have completed my Bachelor Degree in 2014 from Hanoi University of Science and Technology (HUST, a top-tier university in Vietnam), with the School of Electronics and Telecommunications ranked 10/526 students (top 1.9%).
After that, I worked for VNPT Technology Corporation (employees > 1000+) in Hanoi (Vietnam) for 3 years until 2018, mainly doing research and deploying 2G, 3G & 4G mobile communication network projects with various
vendors such as Alcatel-Lucent, Nokia Siemens, and SAMSUNG.
Email /
CV /
Google Scholar /
LinkedIn
|

|
International Conferences and Journals
I take immense pride in my contributions to the academic community, having disseminated my findings through publications in top-tier venues:
ICML (1), ICLR (3), CVPR (4), NeurIPS (2), ECCV (1), Advanced Materials (1, IF: 32), Nano Energy (1, IF: 19), IEEE TCSVT (1, IF: 8.4), IEEE TBC (1, IF: 4.5), IEEE Access (3, IF: 3.9), ICASSP (1).
Reviewers & Program Committee Members
I served as a Reviewer and Program Committee at various prestigious conferences and journals
- ICML 2024, 2025, 2026 [The International Conference on Machine Learning]
- ICLR 2024, 2025, 2026 [The International Conference on Learning Representations]
- NeurIPS 2023, 2024, 2025, 2026 [The Conference on Neural Information Processing Systems]
- CVPR 2023, 2024, 2025, 2026 [The Conference on Computer Vision and Pattern Recognition]
- AAAI 2024, 2025, 2026, 2027 [The Association for the Advancement of Artificial Intelligence]
- ICCV 2023, 2025 [The International Conference on Computer Vision]
- ECCV 2024, 2026 [The European Conference on Computer Vision]
- ACCV 2024 [The Asian Conference on Computer Vision]
- ICASSP 2024, 2025, 2026 [The International Conference on Acoustics, Speech, and Signal Processing]
- AISTATS 2025, 2026 [International Conference on Artificial Intelligence and Statistics]
- IJCNN 2025, 2027 [International Joint Conference on Neural Networks]
- ACM Multimedia 2025, 2026 [ACM International Conference on Multimedia]
- WACV 2026, 2027 [Winter Conference on Applications of Computer Vision]
- ACL 2026 [Association for Computational Linguistics]
- Neural Networks (NN) 2023, Impact Factor: 8.67 [Certificate]
- IEEE Transaction on Multimedia (TMM) 2023, Impact Factor: 7.39
- Computer Vision and Image Understanding (CVIU) 2024, Impact Factor: 4.3 [Certificate]
- ISPRS Journal of Photogrammetry and Remote Sensing (ISPRS) 2024, Impact Factor: 11.83 [Certificate]
- Expert Systems With Applications (ESWA) 2024, 2025, Impact Factor: 8.5 [Certificate]
- Digital Signal Processing (DSP) 2025, Impact Factor: 3.4 [Certificate]
- Transactions on Machine Learning Research (TMLR) 2025
- Engineering Applications of Artificial Intelligence (EAAI) 2025, Impact Factor: 7.5 [Certificate]
- Information Processing and Management (IPM) 2025, Impact Factor: 7.4 [Certificate]
- IEEE Transactions on Circuits and Systems for Video Technology (TCSVT) 2025, Impact Factor: 8.4 [Certificate]
- IEEE Transactions on Emerging Topics in Computing (TETC) 2025, Impact Factor: 5.4 [Certificate]
Awards
- 🏅 Won Best Oral Presentation Award in THE 11th ANNUAL CONFERENCE OF VIETNAMESE YOUNG SCIENTISTS – ACVYS 2025 [Certificate]
- 🏅 Won Jang Youngsil Fellow Program, funded by KAIST. It is the prestigious scholarship offered by KAIST (in South Korea) to support World-Class researchers for Talent Development, 2025 [Certificate]
- 🏅 Won Award of the Top 100 Best Korea National Research, 2023 [Certificate]
- 🏅 Annual Encourage Scholarship by Hanoi University of Science and Technology (HUST) for excellent students with outstanding performance for every semester, 2009 – 2014
- 🏅 Won Trang Nguyen Flower award for the best student among thousands of students in Giao Thuy B High School, Nam Dinh, Viet Nam 2009
- 🏅 Gold Medal: Won First Prize in Mathematics Contest for High School Students in Grade 12, Nam Dinh, Viet Nam 2009
Breaking News
- 2026-07-01 [InnoCORE]: Dr. Trung X. Pham joined the InnoCORE project at KAIST as a postdoc to extend his research on Safety AI, Defensive AI, and Security AI.
- 2026-05-14 [ICML 2026]: Dr. Trung X. Pham was honored to receive the Silver Reviewer Award for ICML 2026 (designated to top reviewers).
- 2026-01-26 [ICLR 2026]: "A Hidden Semantic Bottleneck in Conditional Embeddings of Diffusion Transformers", paper has been accepted to ICLR 2026.
-
>> Oral:
2025-11-09 [🛑] [News]:
Dr. Trung X. Pham delivered a talk titled “Masked Diffusion: The New Frontier of Multimodal Generative AI” at the 11th Annual Conference of Vietnamese Young Scientists (ACVYS 2025) held at Yonsei University, where he received the Best Oral Presentation Award.
- 2025-09-18 [NeurIPS 2025]: "Model-Guided Dual-Role Alignment for High-Fidelity Open-Domain Video-to-Audio Generation", paper has been accepted to NeurIPS 2025.
-
>> Spotlight:
2025-09-05 [🛑] [News]:
Dr. Trung X. Pham has been officially awarded the F-2-7S Talent Visa by KAIST's President and the Korean government, recognizing his global expertise and enabling him to live and work in Korea.
- 2025-09-01 [🛑] [News]: Dr. Trung X. Pham has started his research as a Postdoctoral Researcher at KAIST.
- 2025-07-14 [Reviewers]: Dr. Trung X. Pham has accepted an invitation to serve as a Program Committee (PC) member for AAAI 2026. He will contribute to the paper review and selection process for this leading conference in the Advancement of Artificial Intelligence.
- 2025-06-25 [Reviewers]: Dr. Trung X. Pham has accepted an invitation to serve as a Program Committee (PC) member for WACV 2026. He will contribute to the paper review and selection process for this leading conference in computer vision research.
-
>> Spotlight:
2025-05-29 [🛑] [News]:
🎓 Trung X. Pham has successfully defended his Ph.D. degree in the School of Electrical Engineering at KAIST. His thesis topic: "Multimodal Masked Diffusion-based Generative Models: Innovations and Applications". This marks the completion of his doctoral journey and the beginning of his postdoctoral research career.
- 2025-05-15 [Arxiv 2025]: A Research paper on Zeroshot object customization has been released on Arxiv.
- 2025-05-01 [Reviewers]: Trung X. Pham has accepted an invitation to serve as a Program Committee (PC) member for NeurIPS 2025. He will contribute to the paper review and selection process for this leading conference in AI and neural information processing systems.
-
>> Spotlight:
2025-04-09 [🛑] [News]:
🏅 Trung X. Pham (Ph.D.) has been selected for the 2025 KAIST Jang Young Sil Fellowship Program (Postdoctoral Track). This prestigious program is KAIST’s most competitive fellowship, designed to support the development of world-class researchers. It attracts top talent from around the world.
- 2025-02-22 [CVPR 2025]: "ITA-MDT: Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On", paper has been accepted to CVPR 2025.
- 2025-01-10 [ICLR 2025]: "MDSGen: Fast and Efficient Masked Diffusion Temporal-Aware Transformers for Open-Domain Sound Generation", paper has been accepted to ICLR 2025.
- 2024-08-08 [TBD 2024]: "ACDMSR: Accelerated conditional diffusion models for single image super-resolution", paper has been accepted to IEEE Transactions on Broadcasting (TBD) 2024.
-
>> Spotlight:
2024-08-27 [🛑] [News]:
🎓 Trung X. Pham has successfully defended his Ph.D. Proposal in the School of Electrical Engineering at KAIST.
- 2024-05-02 [ICML 2024]: "Cross-view Masked Diffusion Transformers for Person Image Synthesis", paper has been accepted to ICML 2024.
- 2024-03-25 [TCSVT 2024]: "Learning from multi-perception features for real-word image super-resolution", paper has been accepted to IEEE Transactions on Circuits and Systems for Video Technology (TCSVT) 2024.
- Read More...
Recent Publications
* denotes equal contributions. My research was first recorded in 2018.
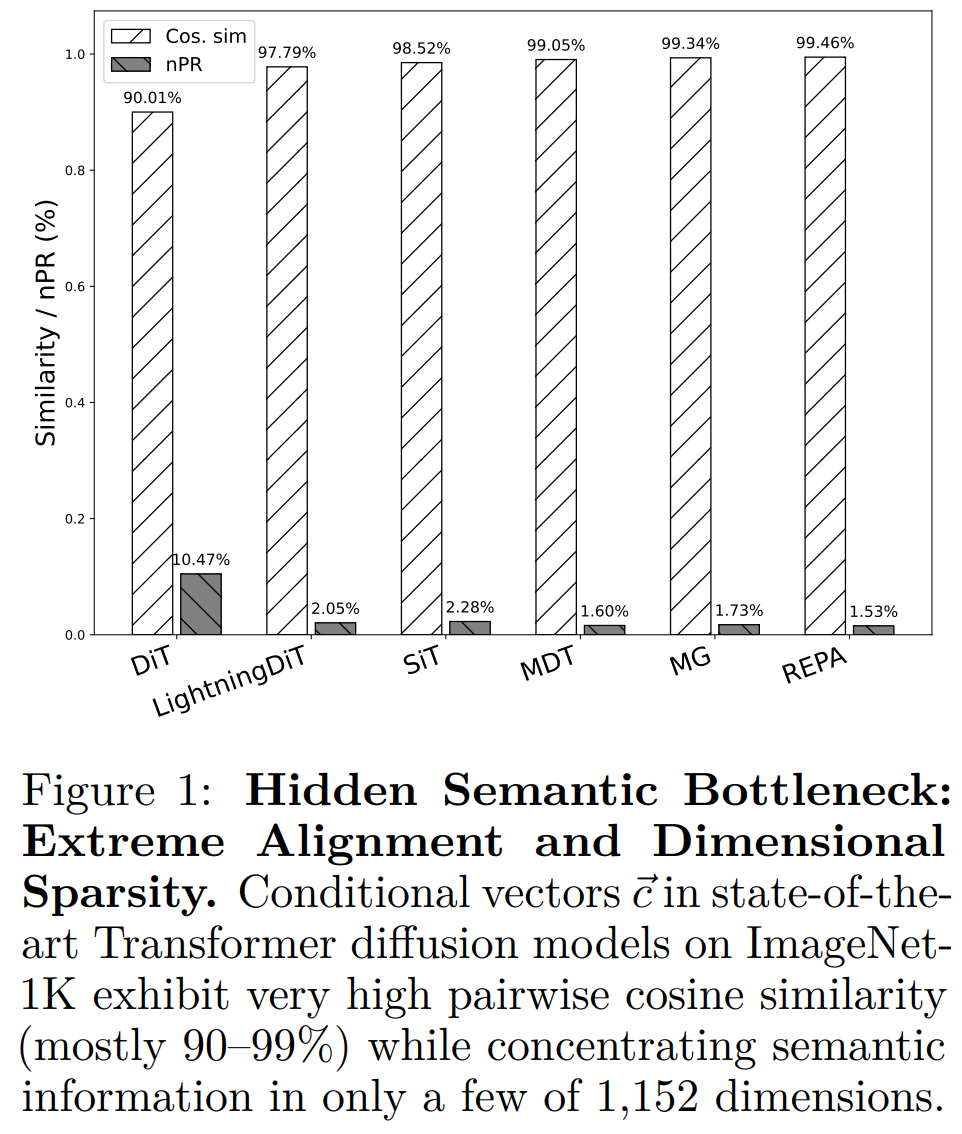 |
[2026] A Hidden Semantic Bottleneck in Conditional Embeddings of Diffusion Transformers
Trung X. Pham, Kang Zhang, Ji Woo Hong and Chang D. Yoo
International Conference on Learning Representations (ICLR 2026), acceptance rate 27.4%, held in Brazil
[OpenReview]
[Code]
We present the first systematic study of these embeddings and uncover a notable redundancy: class-conditioned embeddings exhibit extreme angular similarity, exceeding 99% on ImageNet-1K, while continuous-condition tasks such as pose-guided image generation and video-to-audio generation reach over 99.9%.
|
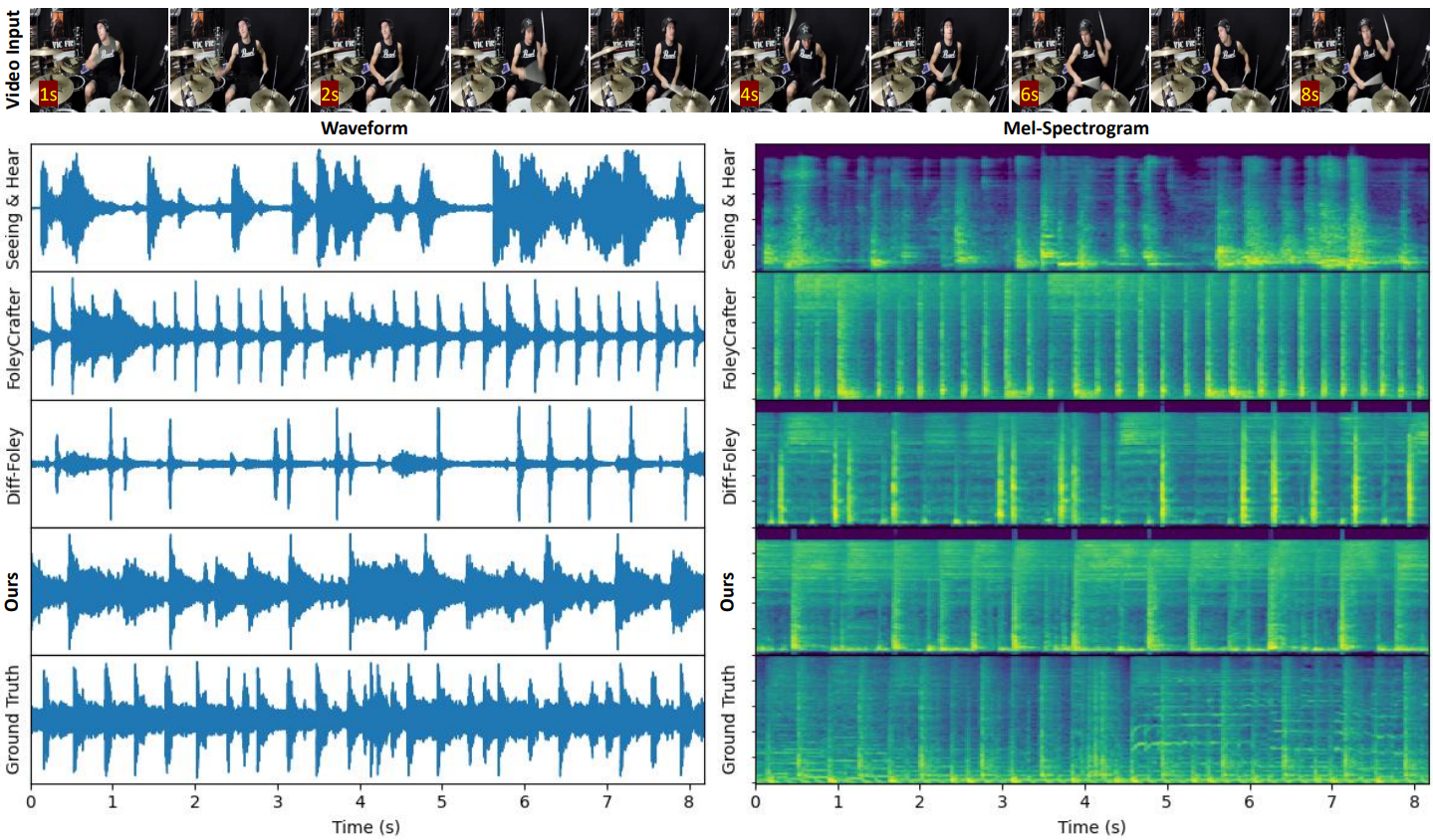
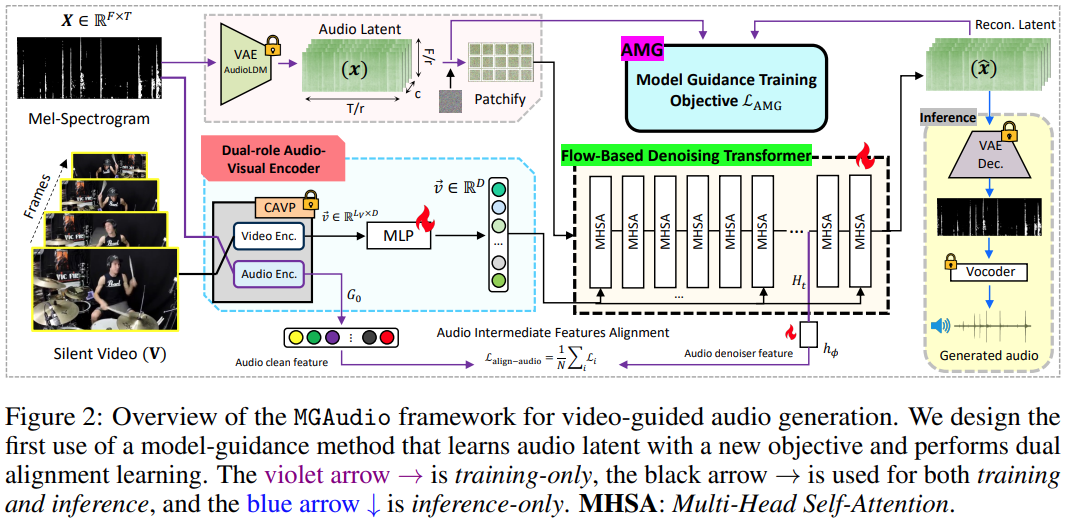 |
[2025] Model-Guided Dual-Role Alignment for High-Fidelity Open-Domain Video-to-Audio Generation
Kang Zhang*, Trung X. Pham*, Suyeon Lee, Axi Niu, Arda Senocak, Joon Son Chung
Neural Information Processing Systems (NeurIPS 2025), acceptance rate 24.5%, held in California, United States of America
[OpenReview]
[Code]
A state-of-the-art framework, a novel framework with model-guidance replacing traditional CFG training for vision-inspired audio generation, outperforms existing state-of-the-art approaches with only 10% of training data.
|
Co-operations
I am open to collaborating with researchers on various topics in Deep Learning, Machine Learning, and AI, including but not limited to Computer Vision, Generative AI, Video/Image/Audio Processing, and Natural Language Processing (NLP).
Feel free to contact me at: trungpx@kaist.ac.kr or phamxuantrungbk@gmail.com
|













![[Certificate]](./static/Best_Oral_ACVYS_2025.jpg){kind=link}
{kind=link}